
How to build end to end analytics in Microsoft Fabric using dltHub and duckdb without spark

Microsoft Fabric is an end-to-end data analytics platform that unifies data engineering, integration, warehousing, science, and business intelligence on a single SaaS platform.
One promising feature is the ability to bypass Spark for your use cases and instead leverage a Python environment with dltHub, MotherDuck, and Streamlit to build end-to-end cost effective analytics seamlessly. More on https://learn.microsoft.com/en-us/fabric/data-engineering/using-python-experience-on-notebook.

The Python experience within the Fabric environment enables you to utilize notebookutils and other Fabric features seamlessly. It operates as a single node with robust hardware specifications, capable of processing hundreds of gigabytes of data efficiently using DuckDB.
Sample use case
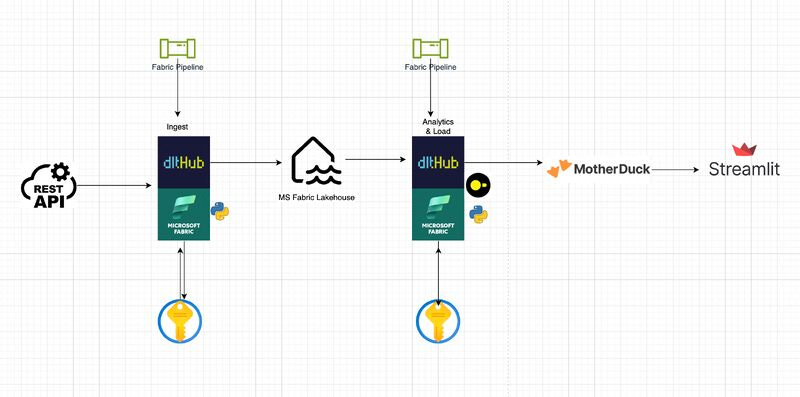
In this very simple use case
(1) Raw breach data is loaded into Microsoft Fabric Lakehouse from https://haveibeenpwned.com/api/v2/breaches using dltHub, a scalable and Pythonic data loading tool.

(2) The raw breach data is then queried and aggregated using DuckDB before being saved into MotherDuck.
(3) MotherDuck token is stored securely in Azure Key Vault.
(4) The aggregated data is then analyzed using Streamlit.

(5) The orchestration of data loading and aggregation is managed through a Fabric pipeline.

Building this example
Notebooks and Streamlit Python code are available at https://github.com/sketchmyview/fabric-dlthub-demo
Lineage
One of the most impressive features, in my opinion, is lineage, which provides a clear view of data flowing through different pipelines and illustrates how data is produced and consumed in relation to one another.

Monitoring
Pipeline and notebook runs are monitored within the Fabric environment and seamlessly integrated into the Azure ecosystem, enabling the creation of robust data observability solutions.
Scheduling
Individual Python scripts can be scheduled to run at specific times (if you are coming with Azure Batch knowledge), or more complex orchestrations can be designed and scheduled within the Fabric environment.

Mix and match
In this use case, dltHub is utilized for data loading, while DuckDB handles the aggregation of data, even at scales of hundreds of gigabytes. However, Spark can be incorporated within the orchestration after data is loaded via dltHub, offering great flexibility. That said, not every use case necessitates Spark.