


From Flat Files in S3 to Smart Insights: Building a RAG System for Northwind Orders Using Amazon Bedrock and Pinecone

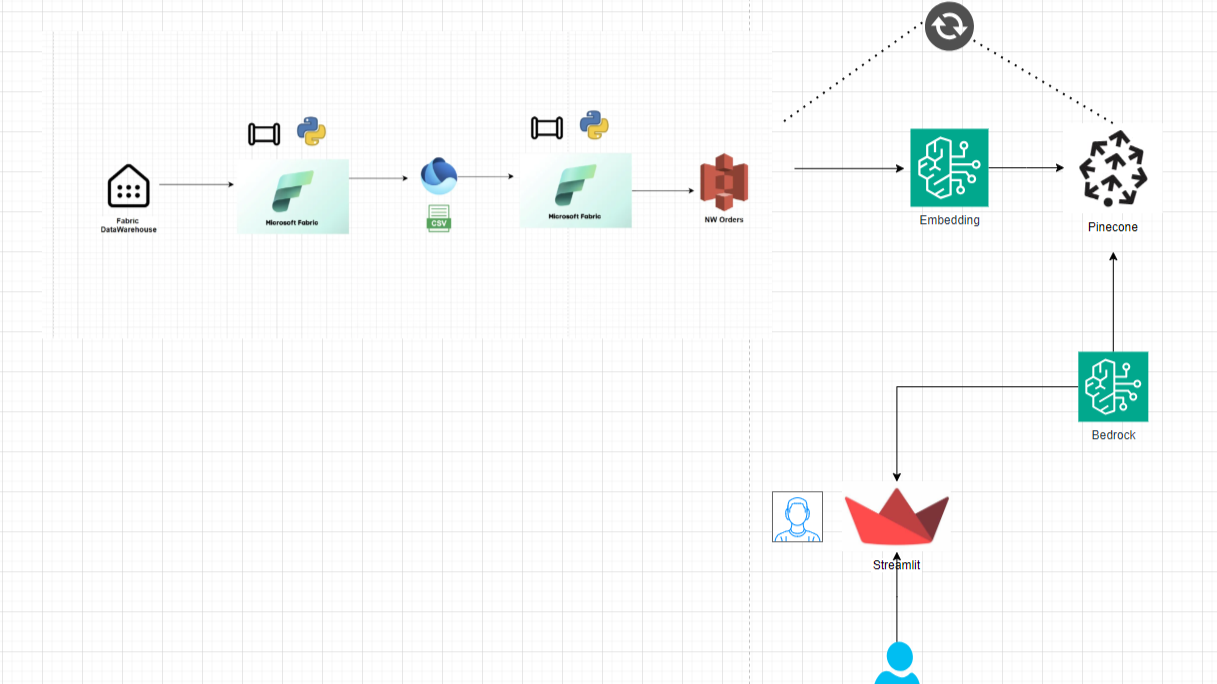
Introduction: Turning Data into Knowledge
In today's data-driven world, businesses thrive on actionable insights. Raw data, even in structured formats like CSV files, often remains underutilized unless transformed into a meaningful knowledge system.
In the first part of our journey, you successfully extracted Northwind's order data from Microsoft Fabric Warehouse and landed it in Amazon S3. Now, the real challenge begins: How do you turn this static dataset into an intelligent system capable of answering complex business queries?
To achieve this, you leverage Retrieval-Augmented Generation (RAG), a cutting-edge AI approach that enhances generative models by incorporating real-time data retrieval.
Unlike traditional AI models that rely purely on pre-trained knowledge, RAG dynamically fetches relevant data before generating responses, ensuring accuracy and contextual relevance.
But before diving into implementation, let's take a moment to understand the dataset you are working with.
Background on the Northwind Dataset
The Northwind dataset is a widely used example database that mimics a real-world business scenario. It contains sales transactions from a fictional wholesale food distribution company, including information on customers, orders, products, suppliers, and employees.
For our purposes, the Orders table is of particular interest, as it provides insights into customer purchasing behaviors, sales trends, and supply chain efficiency.
By applying RAG to Northwind's order data, you can create an AI-powered system that allows businesses to query sales information in natural language and receive instant, data-backed insights.
Step 1: CSV data feed that already arrived in AWS S3
AWS Bedrock lets you directly reference a new order file and start asking questions. It serves as a playground, offering a sneak peek into its capabilities and chunking information.
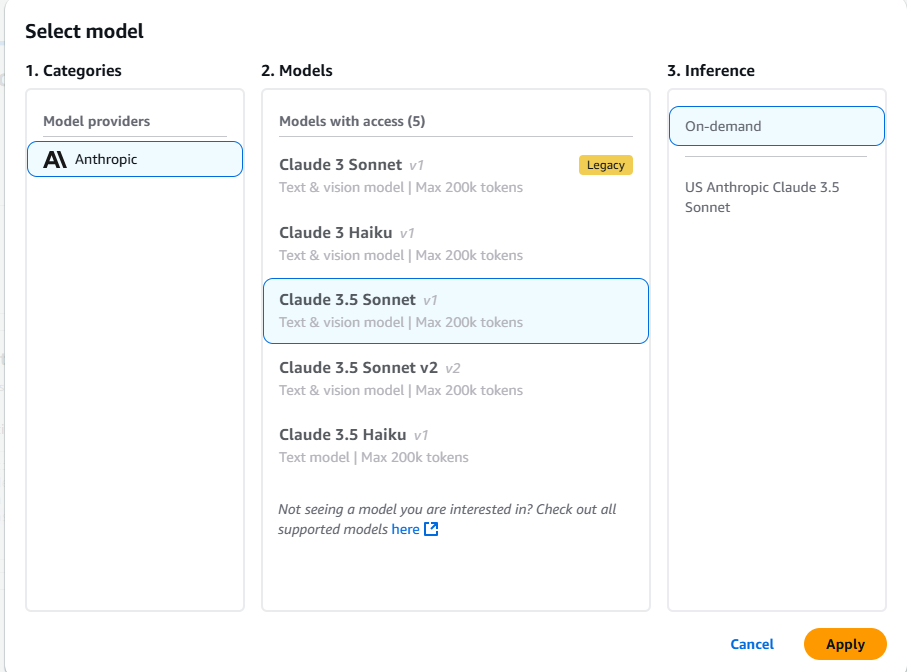
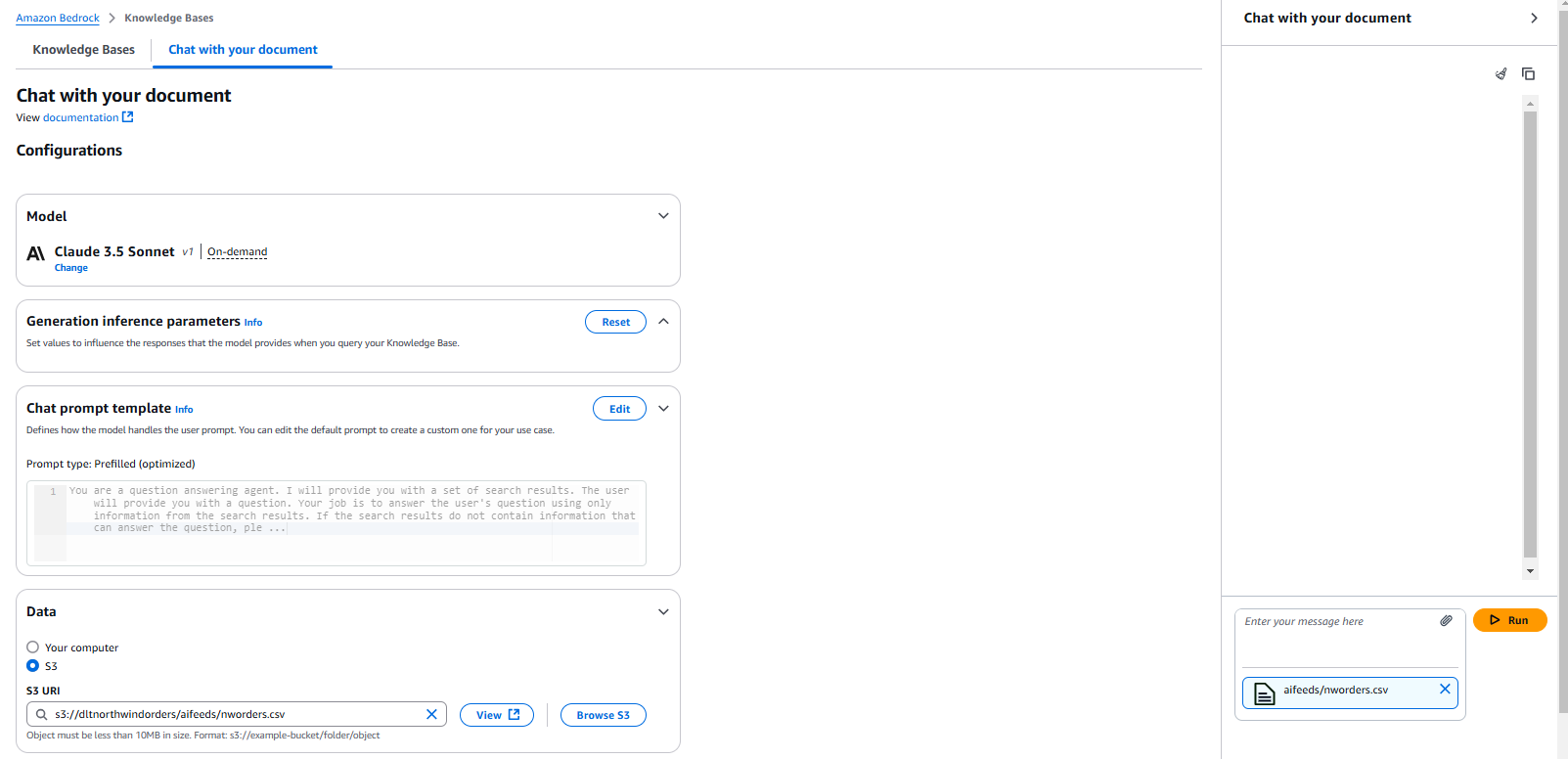
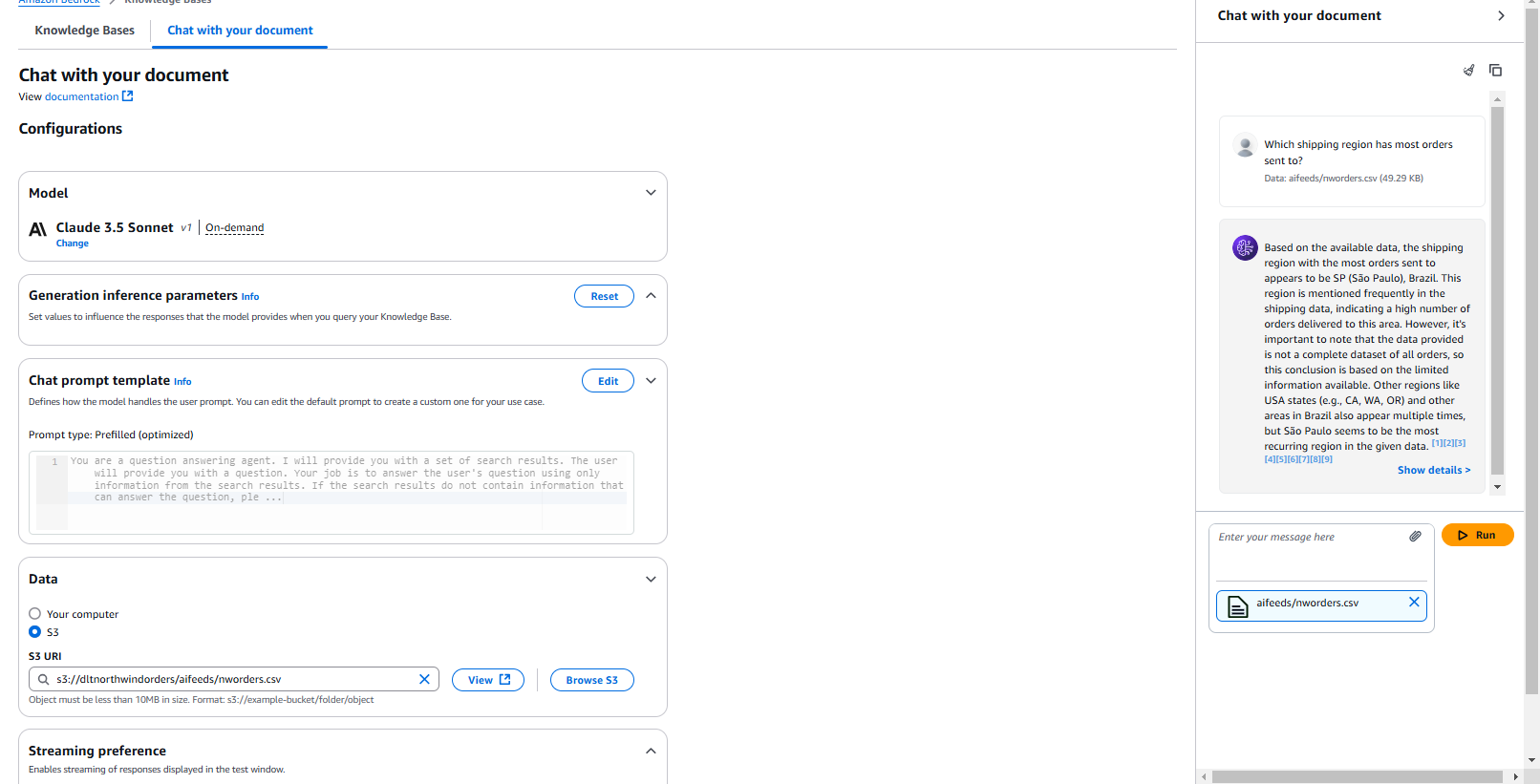
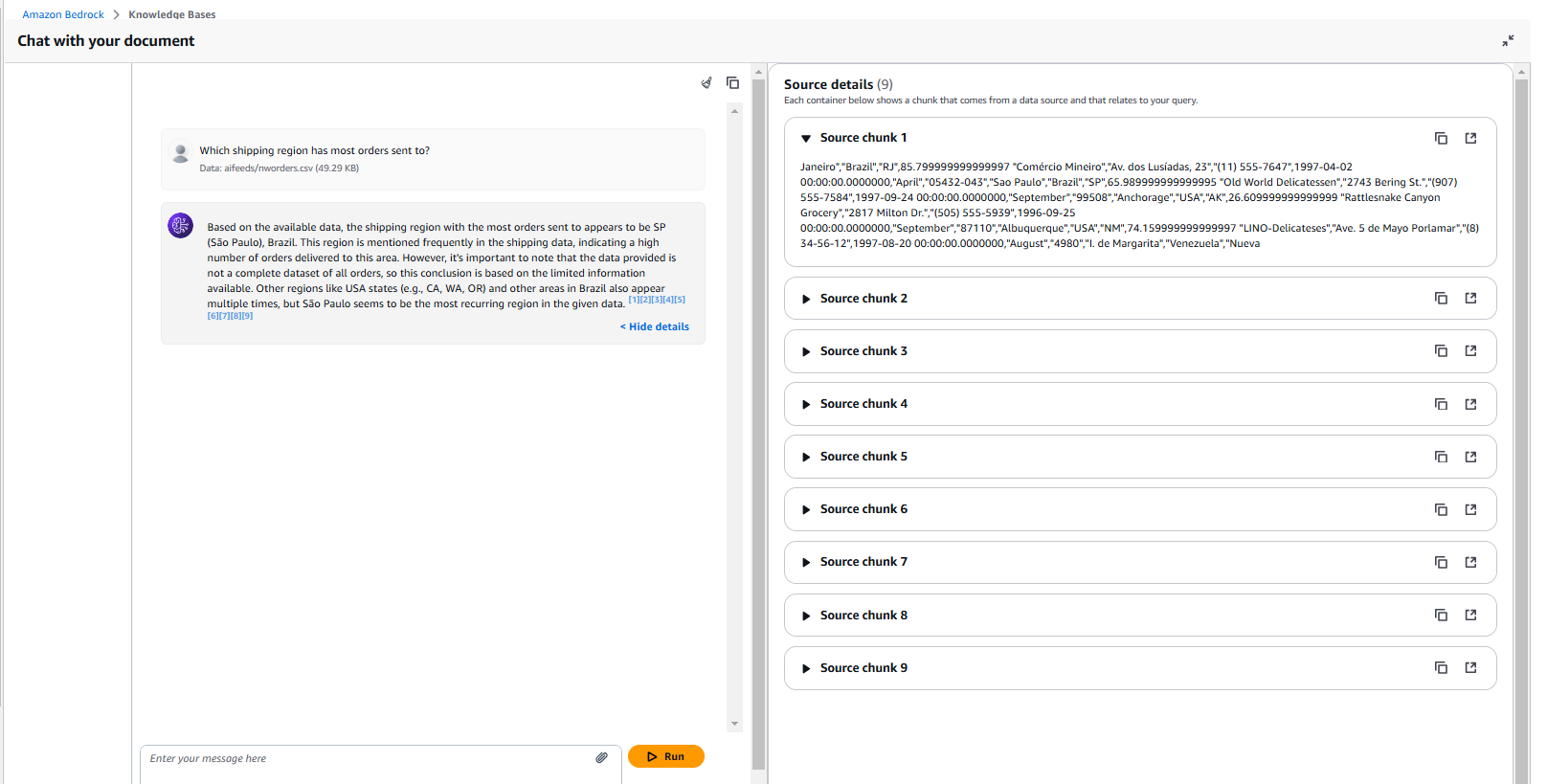
Step 1: Preparing Data for the Vector Database
With our Northwind Orders dataset securely stored in Amazon S3, the first step is to prepare it for semantic search. Traditional databases allow keyword-based lookups, but what if you want to ask more nuanced questions? This is where vector embeddings come into play.
Tokenization & Embedding: Using state-of-the-art language models, you convert order-related text (e.g., customer names, product descriptions, and order details) into high-dimensional numerical representations (embeddings).
Indexing in Pinecone: These embeddings are then stored in Pinecone, a powerful vector database designed for efficient similarity search. This enables our system to retrieve contextually relevant information, even when queries are not exact matches. You can sign up for a free instance at
https://www.pinecone.io/
Complete creation of "Knowledge base" through a set of steps AWS offers
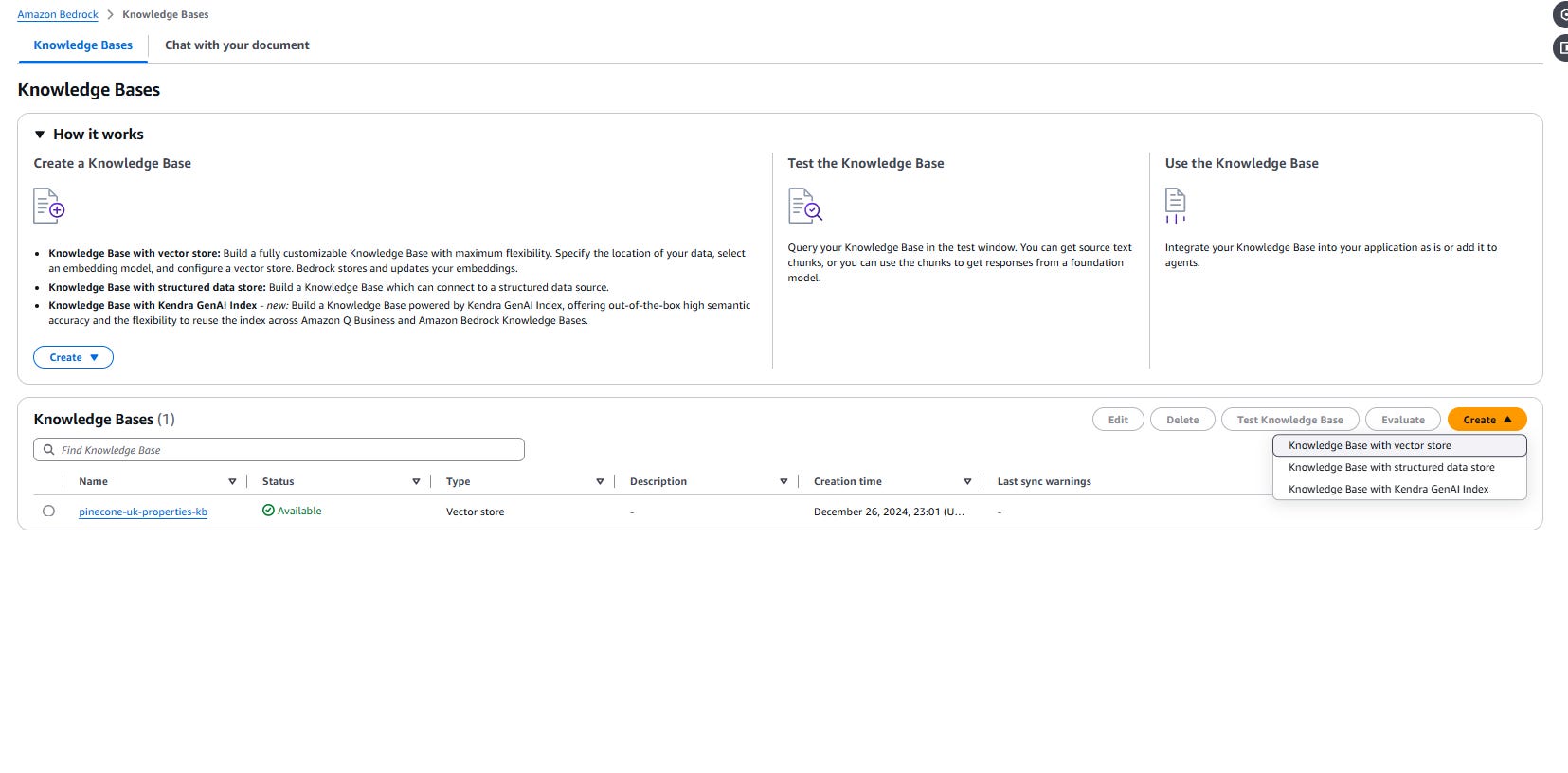
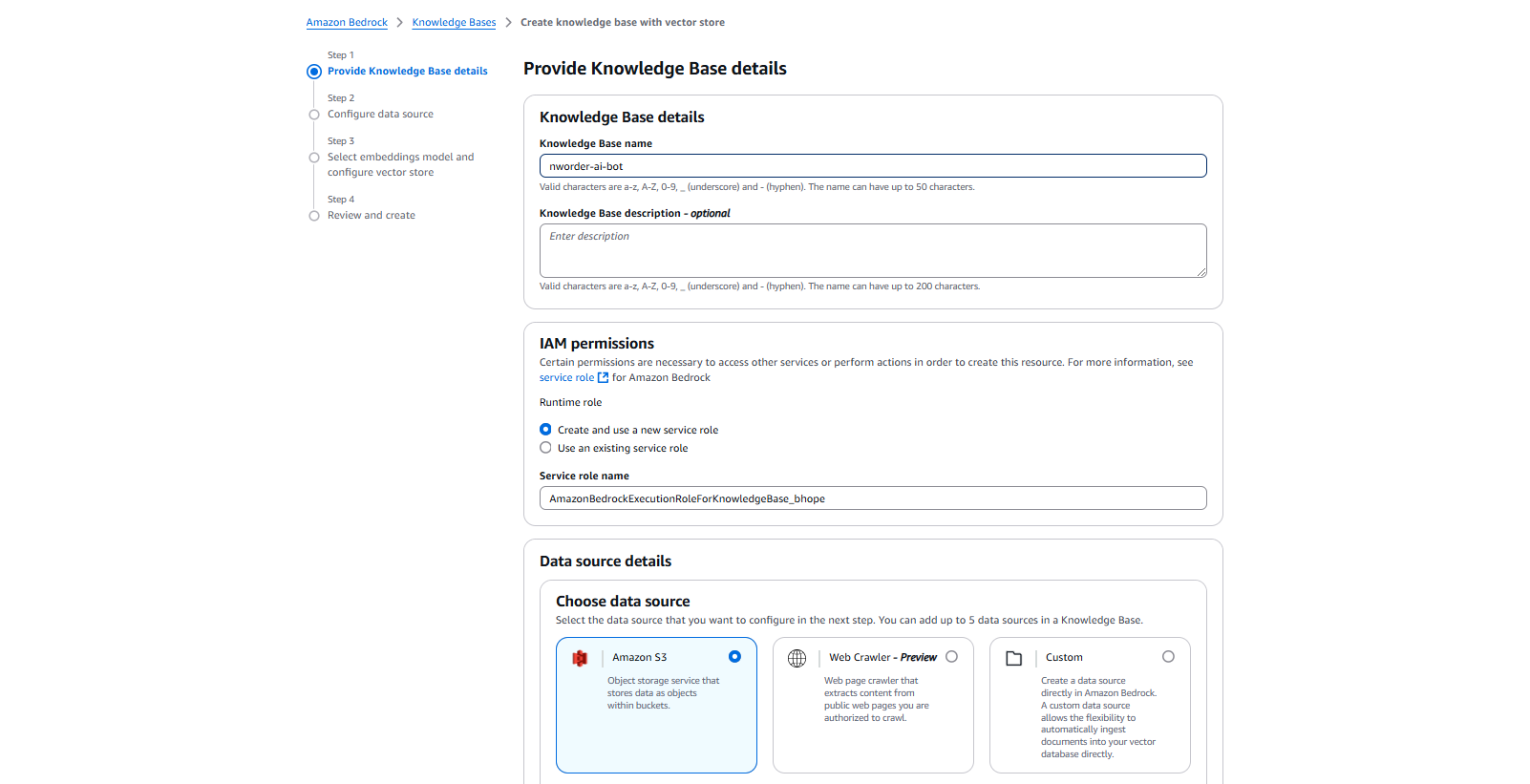
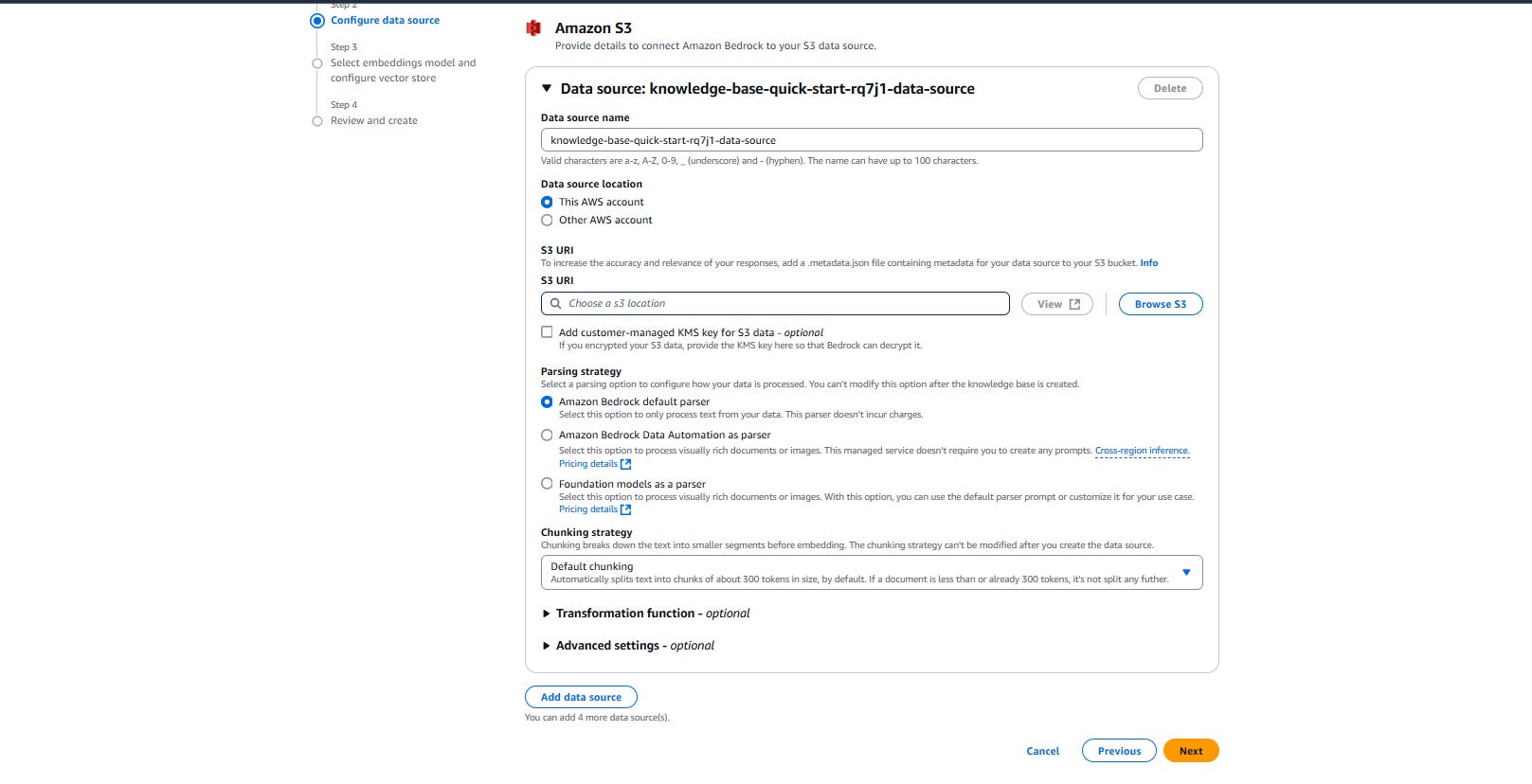
Step 2: Integrating with Amazon Bedrock’s AI Power
Amazon Bedrock provides seamless access to foundation models, enabling businesses to build generative AI applications without extensive infrastructure overhead. You configure a Knowledge Base in Bedrock, linking it to our Pinecone index.
Foundation Model Selection: Among the various options, you leverage Anthropic’s Claude model due to its advanced natural language processing capabilities and efficient retrieval-augmented response generation.
Query Handling: When a user asks a question (e.g., “Which customers placed the largest orders in 2024?”), the query is sent to Bedrock.
Augmented Retrieval: Bedrock queries Pinecone, retrieving relevant order data before feeding it into Claude for a well-informed response.
This setup ensures that every AI-generated answer is grounded in factual business data, reducing hallucinations and improving accuracy.
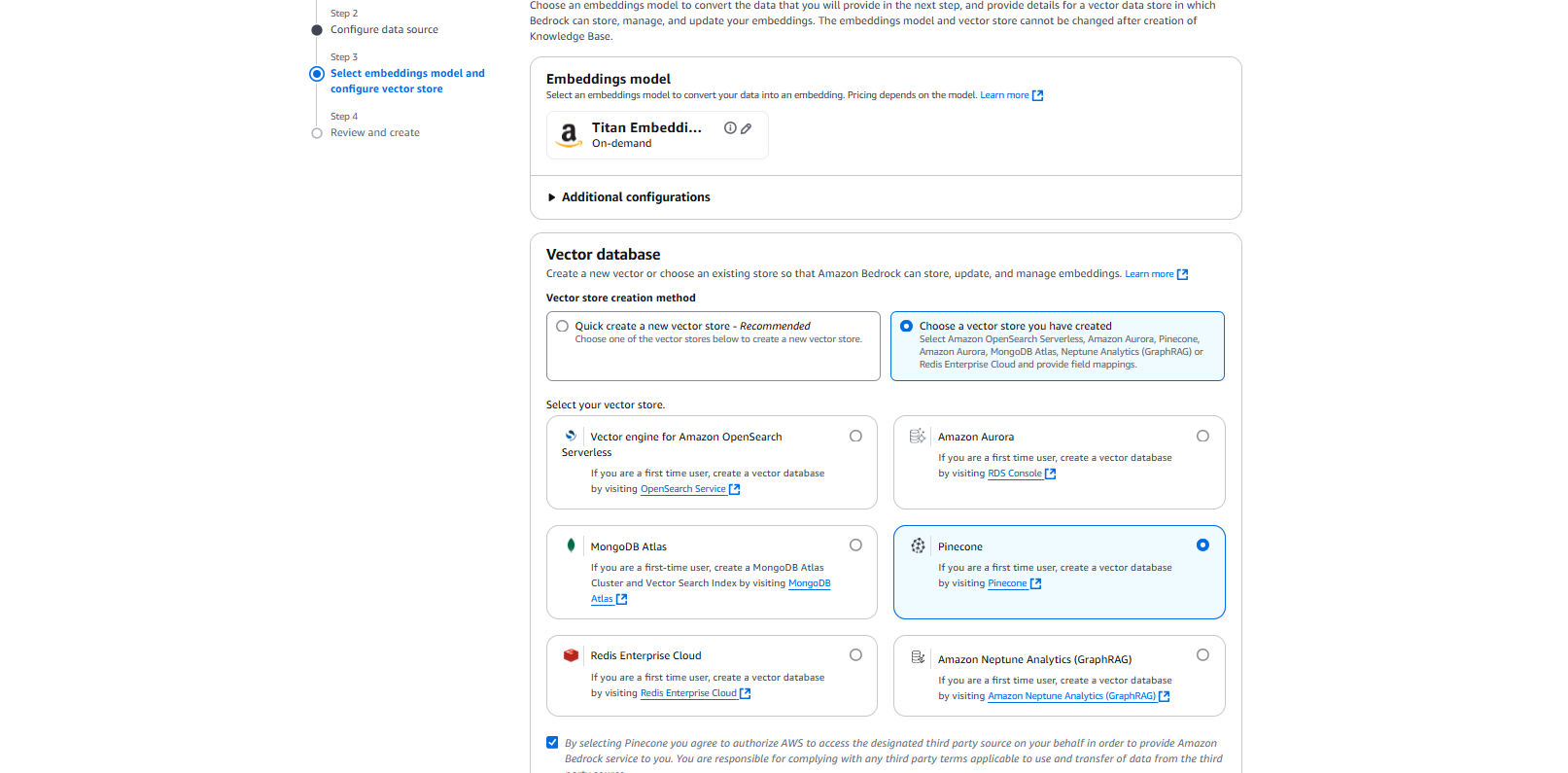
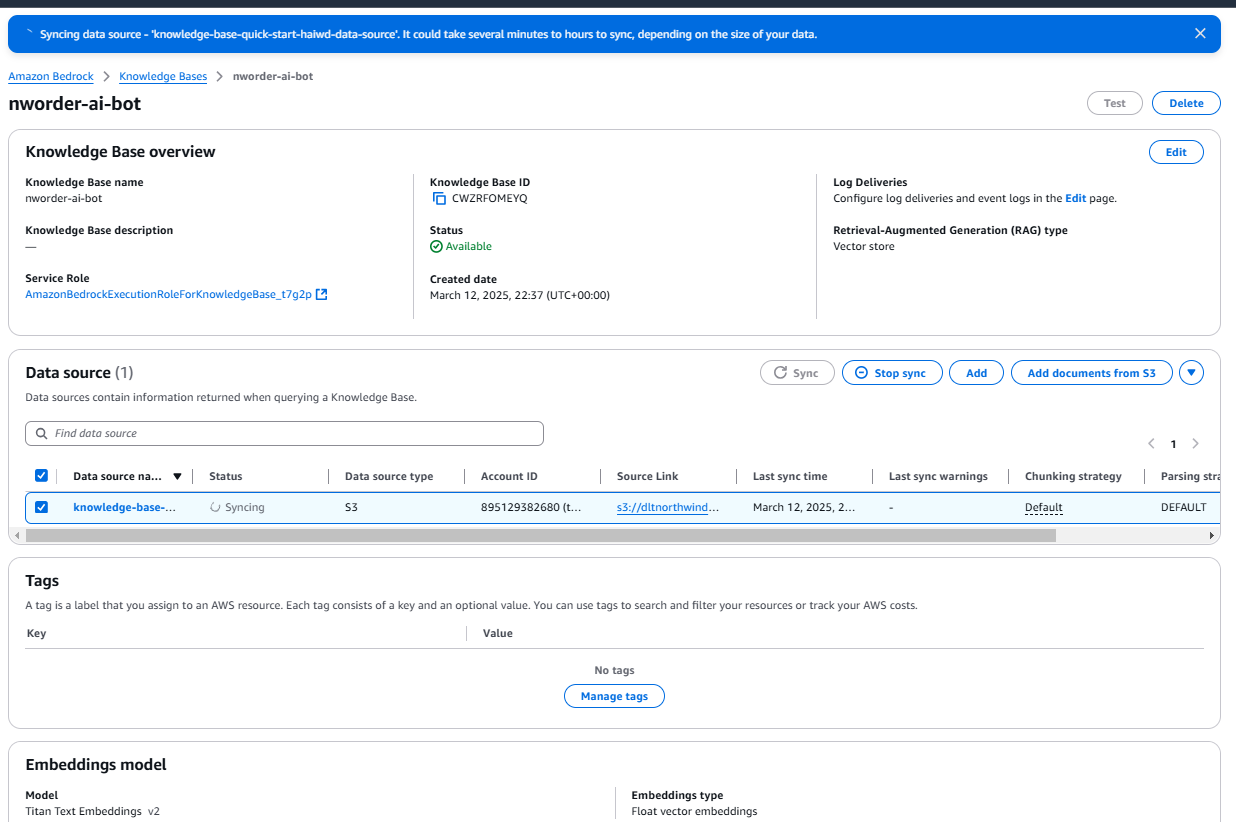
At this stage, our dataset is no longer just a collection of rows and columns; it’s an intelligent, searchable knowledge base.
Step 3: Implementing the RAG System
Retrieval-Augmented Generation (RAG) is a game-changer for AI-driven business intelligence. Unlike traditional AI models that rely purely on pre-trained knowledge, RAG dynamically fetches relevant data before generating responses. Here’s how it works:
User Query Processing: A business analyst asks, “Which month has highest shipping orders sent?”
Semantic Search in Pinecone: Instead of scanning thousands of CSV rows, the system retrieves the most relevant order details using vector search.
Contextual Augmentation: The retrieved data is appended to the query, providing Claude with real-time, business-specific context.
AI-Powered Answer Generation: Claude generates an accurate, data-backed response, complete with product names, sales figures, and trends.
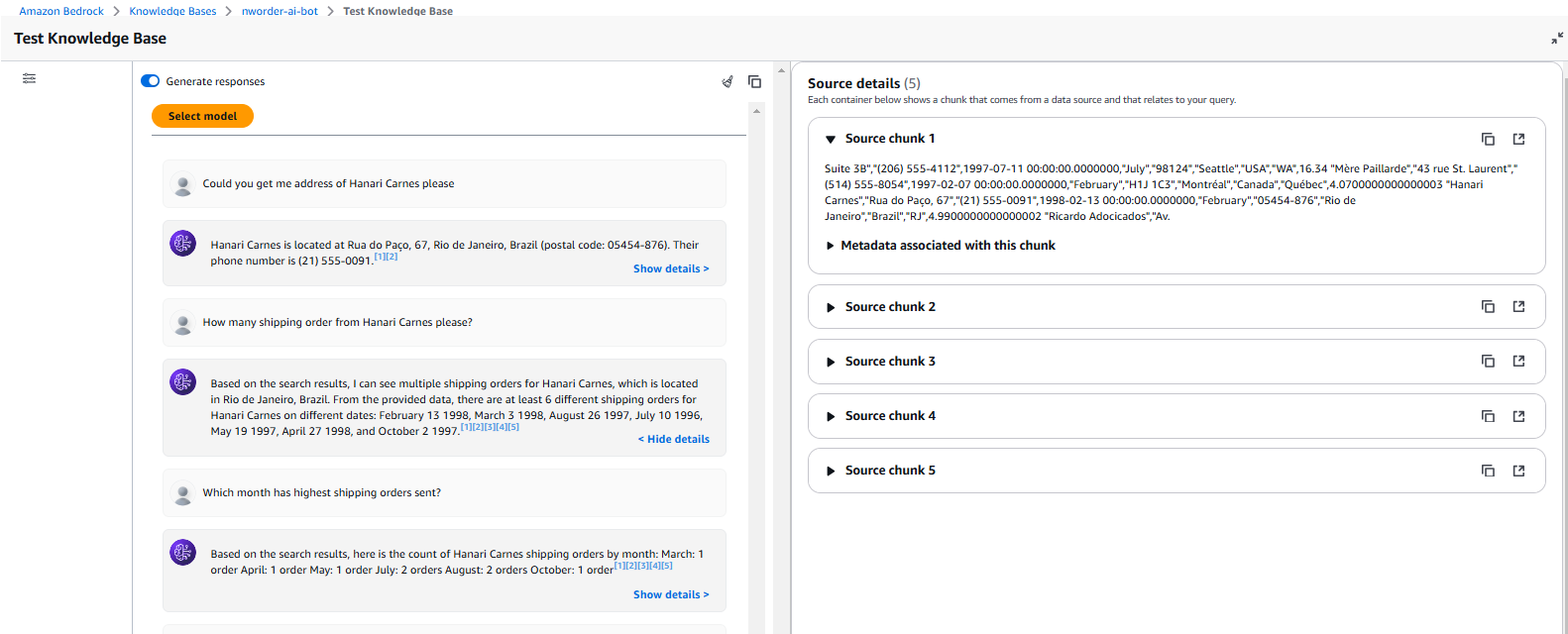
This approach enables businesses to make informed decisions without manually sifting through spreadsheets and reports.
Step 4: Developing an Agentic Application for Real-Time Order Queries
While our RAG system provides insights based on historical order data, real-time queries on live orders stored in AWS RDS require a different approach. To create a truly dynamic system, you develop an agentic application that intelligently directs queries to the appropriate source—either AWS RDS for live orders or the Pinecone knowledge base for historical data.
Self-Learning Task: Build an Agentic Order Query System
As a hands-on challenge, here’s how you can extend this system:
Set Up AWS RDS: Ensure Northwind’s live orders are stored in an RDS instance with proper indexing for efficient query execution.
Design an Agentic Query Flow: Develop an intelligent agent that:
Implement Lambda Functions & API Gateway: Use AWS Lambda to handle query execution, integrating with RDS and Pinecone seamlessly.
Optimize & Expand: Add more intelligence to your agent, such as handling ambiguous queries by suggesting relevant questions.
By completing this task, you’ll gain hands-on experience in developing an AI-powered order intelligence system that balances real-time transactional queries with deep historical insights.
The Impact: Smarter Insights, Faster Decisions
With our Northwind Orders RAG system in place, the benefits are immediate:
Enhanced Decision-Making: Stakeholders can ask complex questions and get instant, data-driven responses.
Scalability & Freshness: As new orders flow into Amazon S3, they can be dynamically indexed in Pinecone, keeping insights up-to-date.
Improved Efficiency: No more manual SQL queries or report generation—AI-driven insights are just a question away.
This transformation showcases how modern AI infrastructure can bridge the gap between raw data and actionable intelligence, empowering businesses to operate with agility.
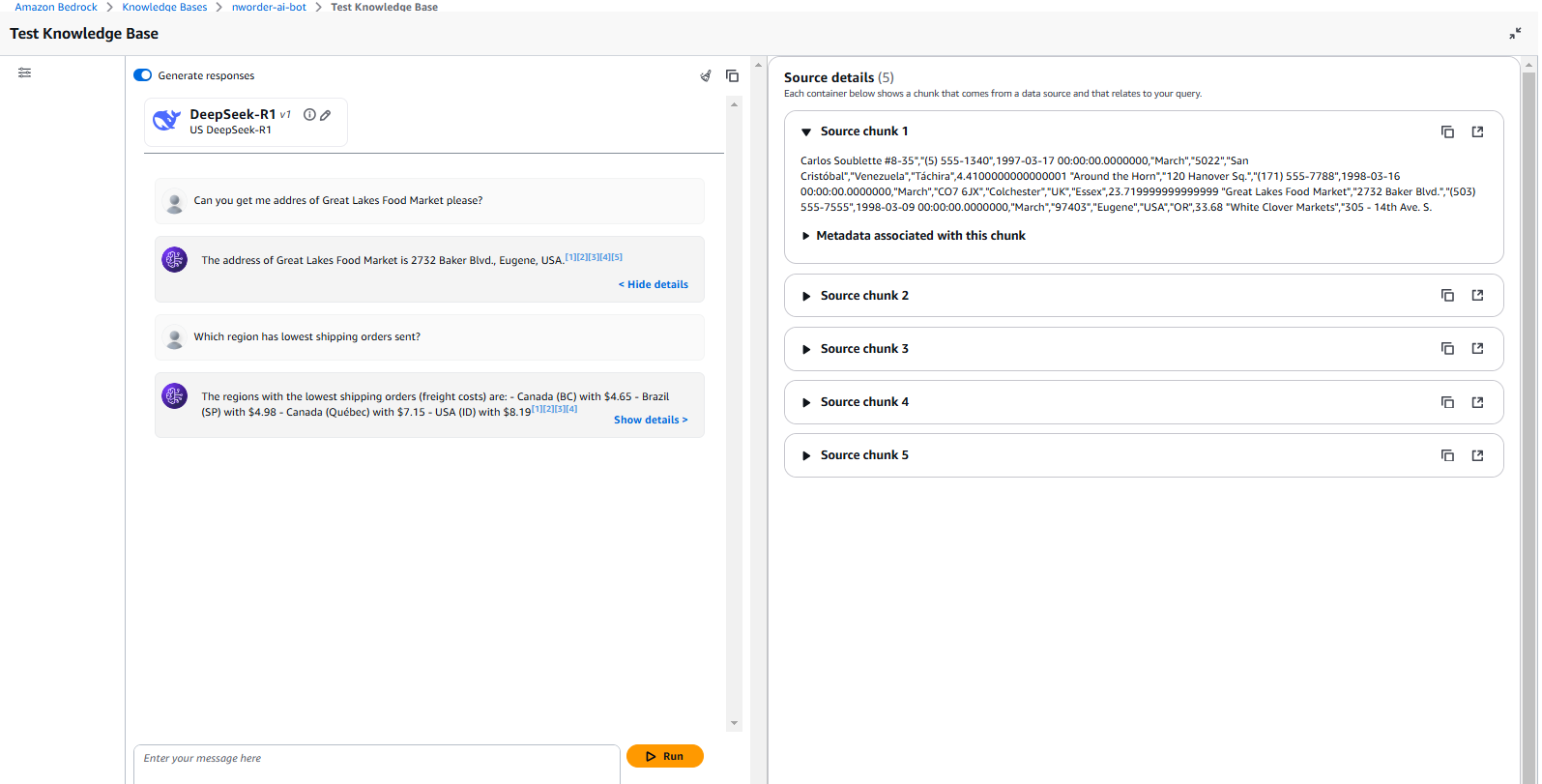
Integration with DeepSeek R1
As of this demo, DeepSeek R1 has been integrated into the AWS Bedrock ecosystem for serverless usage
Conclusion: The Future of AI-Powered Data Analytics
The Northwind dataset is a familiar example, but the real-world implications of this technology are vast. From e-commerce and supply chain management to customer support and financial forecasting, businesses across industries can leverage RAG-based AI systems to unlock hidden insights within their data.
By integrating Amazon Bedrock, Pinecone, and generative AI, youhave successfully transformed static order data into a dynamic, intelligent knowledge base. This is just the beginning—the next frontier involves further automation, real-time analytics, and deeper AI integrations.
Are you ready to bring your data to life? The future of AI-powered business intelligence starts now!