


Extracting Data from MS Fabric Warehouse to AWS S3 - A Practical Data Engineering Example, GenAI Use Case

Introduction
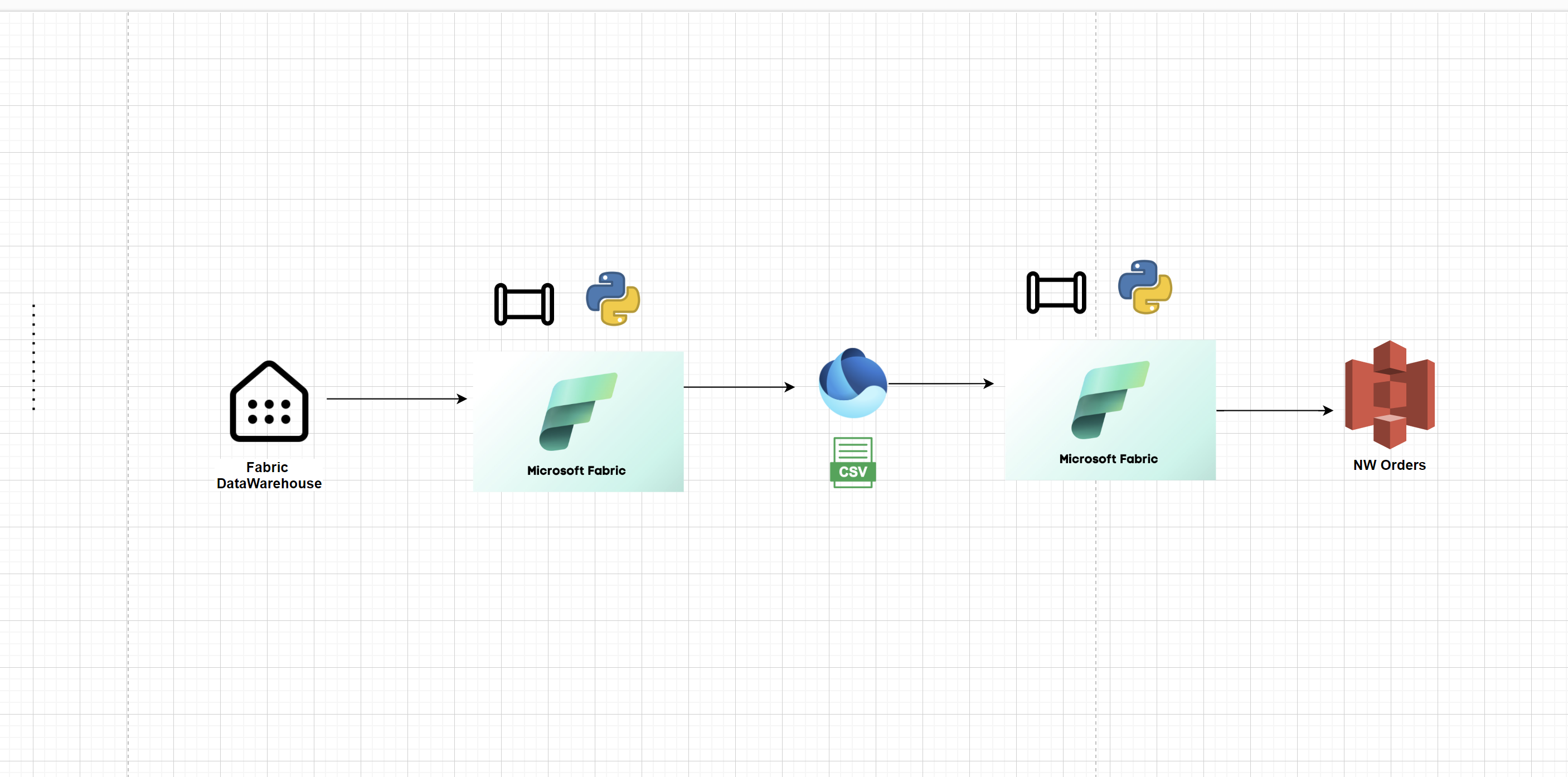
In today’s data-driven landscape, organizations constantly seek efficient ways to extract, transform, and deliver data across platforms. One increasingly common scenario is the need to extract data from Microsoft Fabric Warehouse, process it using Fabric Pipeline, and finally transfer it to a different cloud platform like AWS S3 for downstream consumption.
This article walks through a real-world implementation of this pipeline, highlighting the technical components and security best practices involved.
Additionally, I’ll also touch upon how this work sets the foundation for an AI Data Product Lifecycle, where a team is building a RAG-based GenAI application using the extracted data.
End to End MS Fabric Pipeline
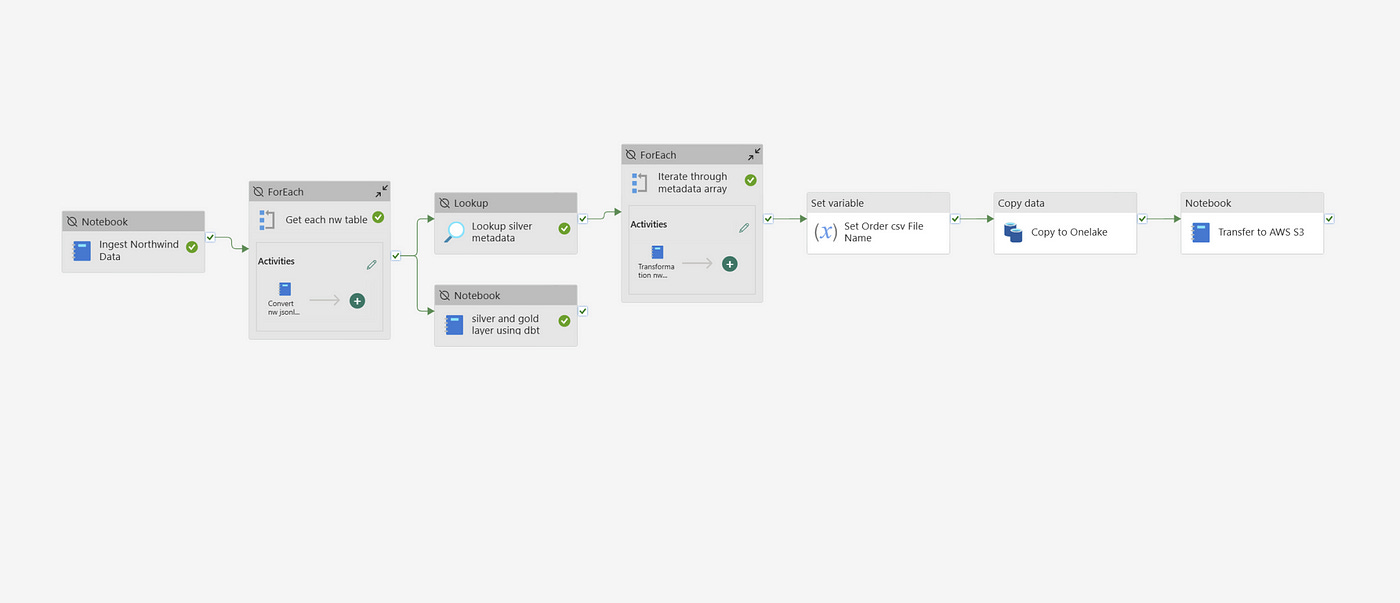
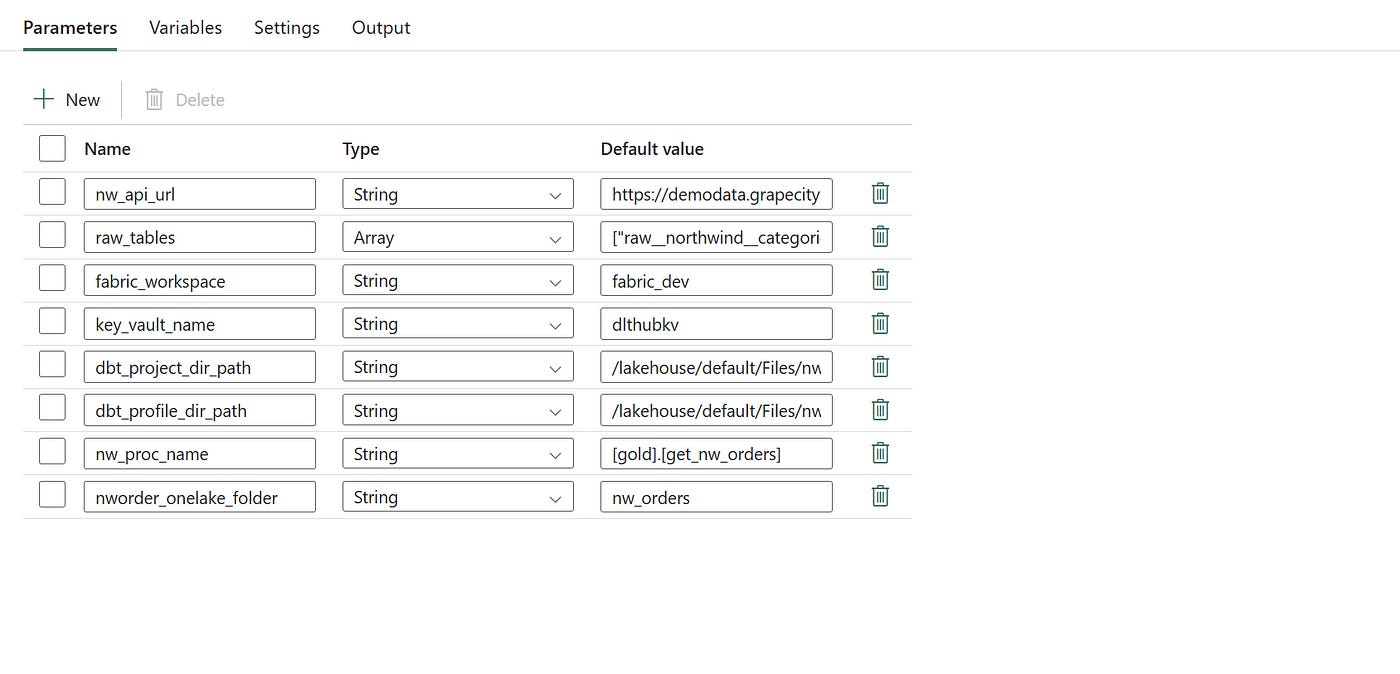
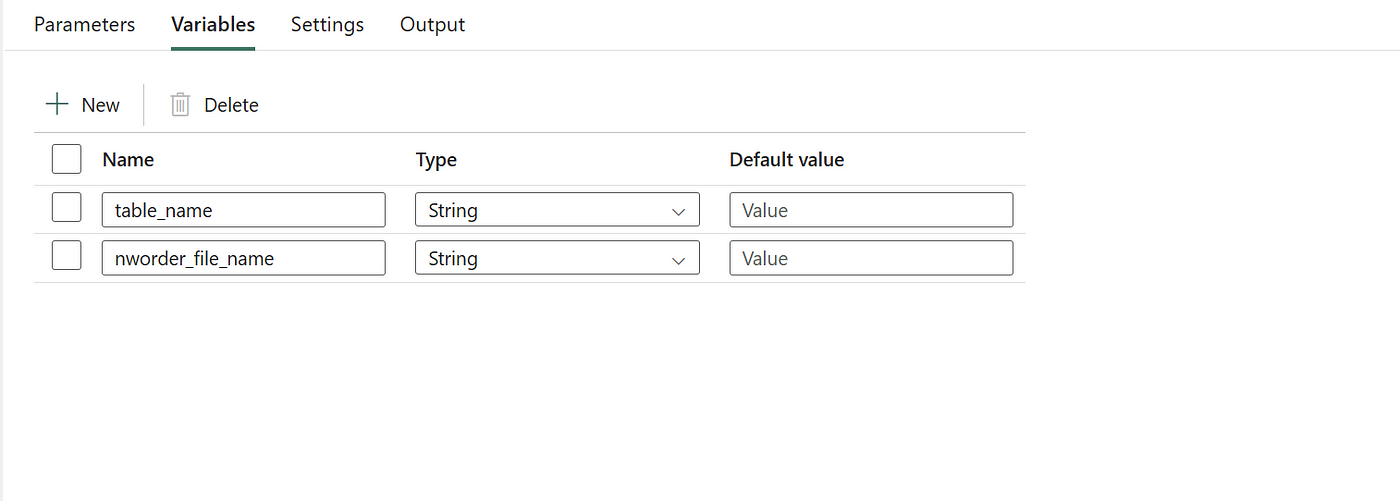
This is the approach you follow to organize the Pipeline in MS Fabric. You define a set of activities, configure parameters, and create a few variables — such as a file name — that can be stored in a variable for later use when saving the file to OneLake as a CSV.
This approach also helps you manage and pass dynamic values across different Fabric environments.
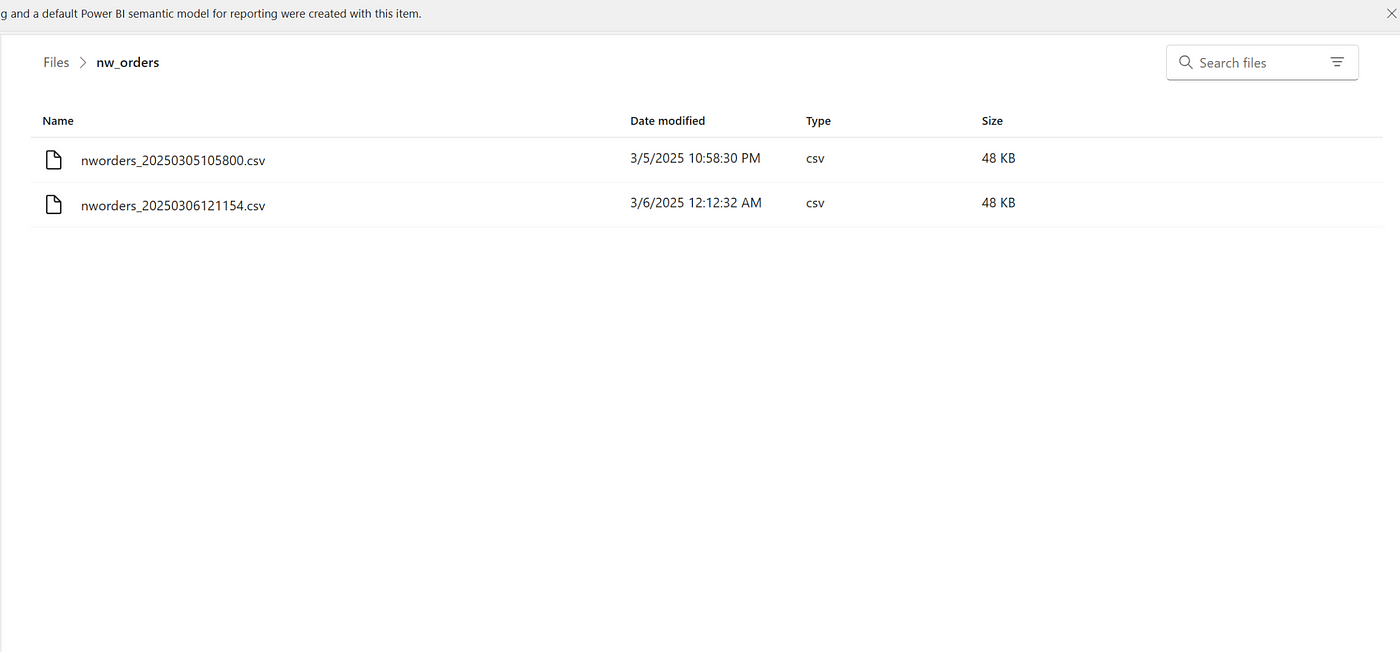
Defining the File Name with Timestamps for Auditability
In any data extraction process, file naming conventions play a critical role in enabling traceability, version control, and auditability. Our process begins with dynamically setting the output file name within the Fabric Pipeline. The file name is a combination of descriptive text (indicating the source or content) and a timestamp that captures the exact extraction time.
Example file name format:
nworders_20250306121154.csv
This approach ensures that every extracted file is unique and can be traced back to its extraction run, which is essential for both audit requirements and debugging purposes.
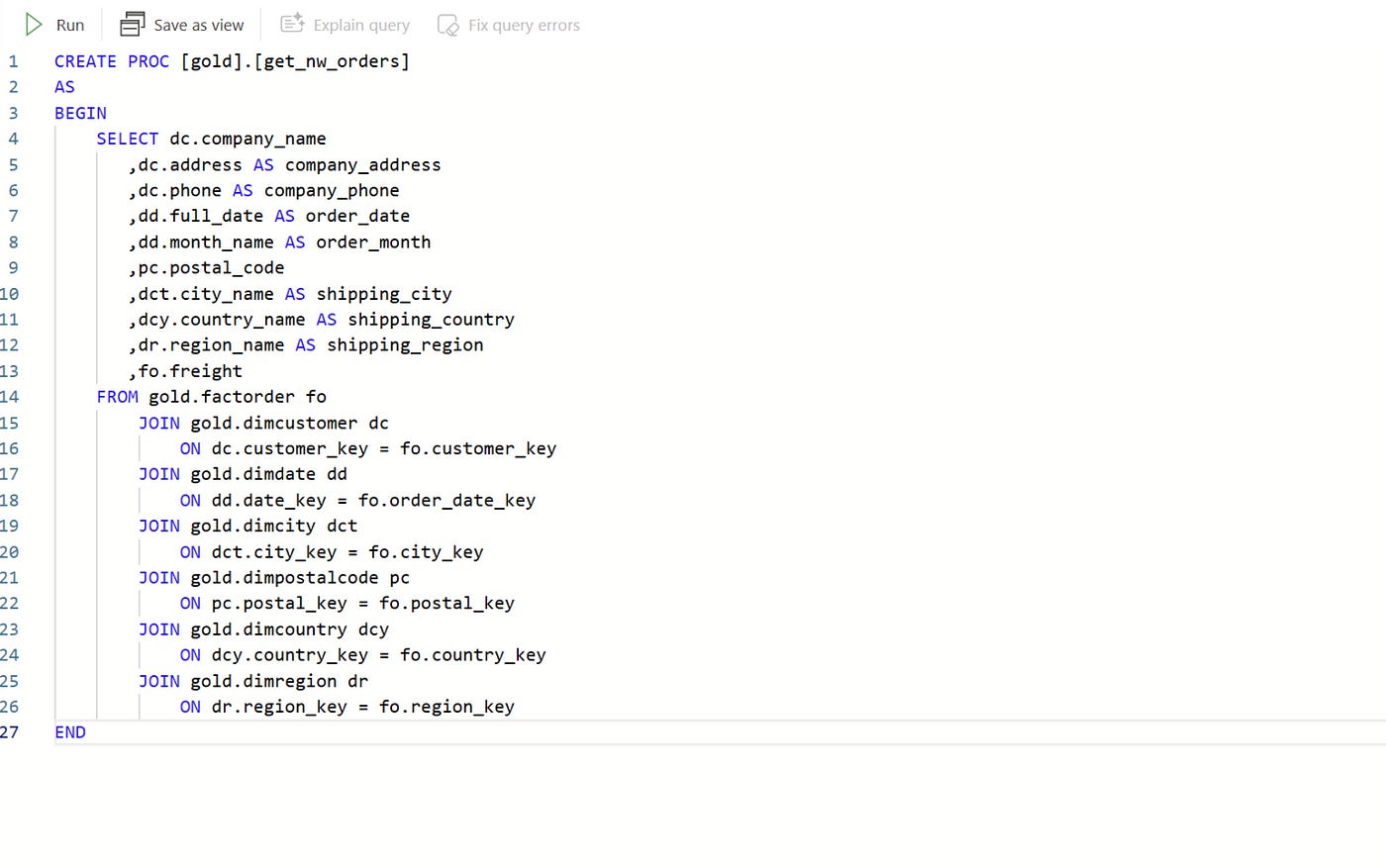
Querying Data from a Star Schema via Stored Procedure
The next step in the pipeline is to query data from a star schema housed in the MS Fabric Warehouse. A stored procedure is used to encapsulate the query logic, ensuring that business rules and transformations are consistently applied every time data is extracted.
This stored procedure retrieves data from the fact and dimension tables within the star schema, aligning with typical data warehousing best practices. By centralizing this logic within a stored procedure, any future changes to business rules can be managed directly in the warehouse without modifying the pipeline itself.
Step 3: Copy Activity — Writing Data to OneLake as a CSV File
Once the data is queried, the Fabric Pipeline’s Copy Data activity is used to write the data to OneLake in the form of a flat CSV file. OneLake serves as the centralized storage layer within Microsoft Fabric, ensuring compatibility with other Fabric workloads.
This CSV file becomes the intermediate output in our data movement process. Storing in OneLake also enables additional data quality checks or transformations if required before the file is handed off to downstream systems.
Step 4: Secure Transfer to AWS S3 using Boto3
The final step in the pipeline involves transferring the file from OneLake to AWS S3. This is accomplished using a custom Python activity within the pipeline, leveraging the popular Boto3 library for interacting with AWS services.
One key requirement here is to ensure that the file name in S3 is static to support downstream consumers who expect to always process the latest file under a fixed name (e.g., Northwind_Orders_Latest.csv). This pattern is common in many data integration scenarios where downstream processes do not have the capability to dynamically locate files based on timestamps.
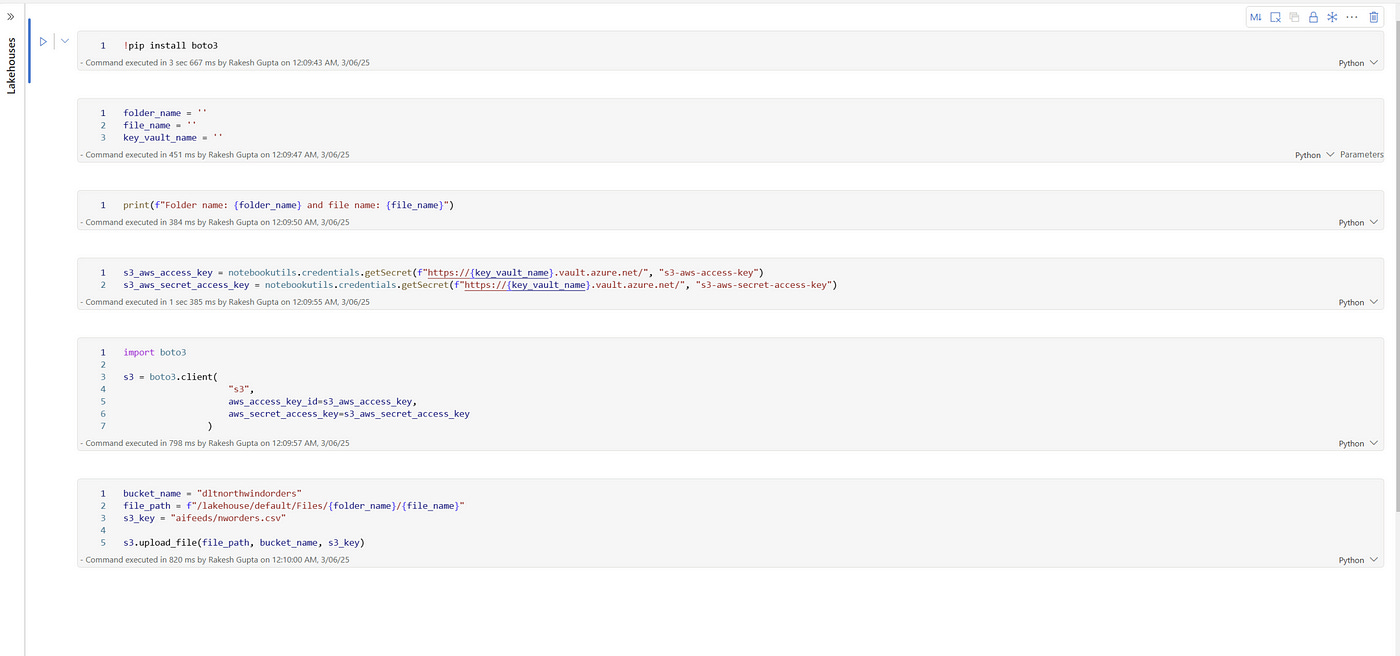
Security Considerations — Azure Key Vault Integration
Security is a top priority in this design. All credentials required to access OneLake, Fabric Warehouse, and AWS S3 are stored in Azure Key Vault. The pipeline retrieves these secrets at runtime, ensuring that no credentials are hardcoded within the pipeline code or configuration.
This follows the principle of least privilege, minimizing exposure and ensuring that credentials are only accessible by authorized resources.


From Data Extraction to AI Data Product
This pipeline is not just a standalone data integration exercise — it’s part of a broader data product lifecycle. Another team is working to build a RAG-based GenAI application powered by the data extracted from Microsoft Fabric Warehouse. This application uses:
AWS Bedrock for access to LLMs (large language models)
Pinecone for efficient vector search
Streamlit to build the user interface for interacting with the AI Agent
This is a great example of how data engineering and GenAI applications converge in a modern data product lifecycle. The data has passed through the full lifecycle:
Data Ingestion from Fabric Warehouse
Data Transformation within Fabric
Data Quality Checks to ensure clean and trusted data
Data Delivery to AWS S3 for AI application consumption
The Role of Data Engineering in AI Product Lifecycle
This end-to-end scenario highlights a critical point: AI is only as good as the data it is built on. While GenAI and RAG (Retrieval Augmented Generation) have grabbed headlines, these models rely on high-quality, well-governed data to deliver accurate and meaningful results.
Without solid data engineering work — from schema design to secure pipelines, auditability, and data quality controls — the AI Agent would be operating on shaky ground. This project serves as a textbook demonstration of data engineering’s pivotal role in making AI products successful.
Key Takeaways
Here are some key lessons for data engineers, architects, and AI teams:
Standardize file naming conventions for auditability and traceability.
Use stored procedures to encapsulate business logic within the warehouse.
Leverage OneLake as the central data lake within Microsoft Fabric.
Use Python (Boto3) for flexible data transfer between clouds.
Manage all secrets via Azure Key Vault to ensure secure credential management.
Treat data pipelines as part of the AI product lifecycle, not isolated infrastructure.
Collaborate early with AI and application teams to understand data requirements.
Final Thoughts
This example highlights the real-world complexity behind seemingly simple data movements. Every step — from query design to file naming, from security to downstream compatibility — contributes to building a robust data foundation for AI and analytics use cases.
As organizations move towards building data products rather than just pipelines, this mindset shift becomes crucial. Data engineers must not only think about moving data, but also about how data will be used, what quality guarantees are needed, and how to embed security into every layer.
This is the essence of modern data engineering — and this project is a great case study of how it all comes together.
How to use the github repo
All the necessary code can be found in the GitHub repository by weeks (week4): [https://github.com/sketchmyview/fabric-dlthub-series]
Import the pipeline and notebooks from their respective Pipeline and Notebook folders into the Fabric environment.
Self-Challenge for Data Engineers: Can You Make This Event-Driven?
In the example pipeline I described, the process of csv transfer to AWS S3 is orchestrated via Fabric Pipeline activities running sequentially. But what if we wanted to make this event-driven instead?
The Challenge: Event-Driven Data Movement
Here’s your challenge:
1) As soon as the CSV file lands in OneLake, trigger an event.
2) The event should carry file metadata (file name, path, timestamp).
3) Based on the event, automatically invoke a Python script (perhaps in Azure Function or Container Apps) to:
Read the file from OneLake
Transfer it to AWS S3 using Boto3
Apply any post-transfer logging or notification (e.g., send a Teams or Slack message)
Bonus: Advanced Twist
For those who want to go a step further:
1) Can you enrich the event with data quality metrics (row count, file size, schema conformity) before triggering the transfer?
2) Can you publish this event to a message queue like Event Grid, Azure Service Bus, or even Kafka to make this part of a larger data product ecosystem?
3) After transfer, can you automatically register this file in an S3 Data Catalog (like AWS Glue) for downstream discoverability?